
ECMWF Summer of Weather Code 2019
Published:
The four month Summer of Weather Code project has drawn to a close. The codebase can be found on Github here. The process has been hugely informative and incredibly fun.
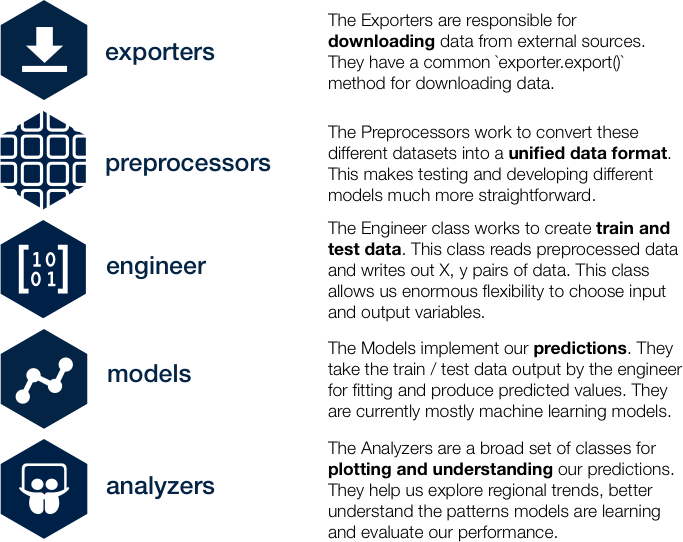
Our Summer in Numbers
Gabi and I have been writing code together almost every day from June through to the end of August. Some of the numbers speak for themselves.
We have made 131 commits to Master branch. These have all been Squash and Merge commits and so the number of total commits is at least 10x bigger than that number.
We have written 18,544 lines of Python code including 181 unit tests! These are all run automatically using Travis Continuous Integration. For me, as a PhD student with no experience in software engineering this has been a massive learning curve. The ability to develop a complex code-base as part of a team has been made possible by learning about unit testing. Luckily, there are no statistics (yet) on how many of my / Gabi’s tests passed because I had ALOT of failing tests…
In order to work together over national borders and time zones we used Slack to stay in contact. We sent over 15,600 Slack messages just to each other!

What have we learned?

Working with climate data can be really messy! Having large multi-dimensional arrays can cause memory issues both in terms of storage and processing. We probably required slightly bigger computers to run the experiments that we wanted to. Machine learning tools are well suited to working with these multi-dimensional arrays however, ensuring that the tensor indices align can be a challenge. Luckily tools like xarray make working with these multi-dimensional datasets much simpler!
Software development techniques can really help scientists! By working with Gabi I have learned so much about writing good code. By using static typing, working with GitHub, and having unit tests run through continuous integration, these processes really help avoid pain in the future and make it easy to build out functionality.
Working at the interface of climate science and machine learning can lead to really interesting questions and answers. We were focused on producing accurate predictions of vegetation health and interpreting the importance of different input features. However, once you begin to look for applications of Machine Learning in Climate Sciences a whole world of possibilities opens up. These range from improving parameterisations, to learning symbolic representations of a dynamical system from data.
What next?
We have built something that we can be incredibly proud of. However, as with all good projects there is a lot left to do!
The future roadmap can be split into three components. Algorithms, the Pipeline itself and Experiments.
Algorithms
It would be great to implement a convolutional neural network to better account for spatial structures in the model. This would allow us to test whether the remaining error is reduced by accounting for spatial covariability.
I would also like to implement gradient boosted regression trees. They are useful baseline models that tend to work very well out of the box. The reason we did not implement them earlier is that we were unable to read our data into memory.
Pipeline
We have the functionality to run the pipeline at different temporal scales. We have currently run it at a monthly timescale because this reduced our data requirements. However, I want to test the pipeline for daily timesteps in order to prove its efficacy at shorter lead times.
Experiments
Finally, we want to experiment with different target datasets and incorporate the dynamical forecast data. Choosing a different target dataset (SHOULD) be relatively straightforward.
Working with the seasonal forecast data from S5 might prove a tougher challenge. It was something we were aware of and the pipeline has the ability to use the data. However, the functionality was never properly tested and so that will likely require some work.
Ultimately, I hope to continue to use the pipeline to produce papers for my PhD. I am confident that it is a really useful tool for answering a variety of questions. This also means that I can continue to contribute to it!
Thanks to you!
A final few words of thanks. Thanks to my supervisors Simon and Steve for their patience and interest in the project. Thank you to ECMWF, Copernicus and our mentors, Julia, Claudia, Stefan and Shaun. The Summer of Weather Code project has been a massive learning curve and I am really excited to continue to develop the code and these relationships through my PhD.
Finally, thanks to Gabi my project partner. I was lucky to have met Gabi and been able to work with him over this time period. Our skills were incredily complementary and I now know what it means to be part of a successful team. We had constant discussions about our ideas and how to implement different parts of the pipeline but ultimately we were both committed and gave sufficient time to the project to see it flourish. I couldn’t have hoped for a better person to be working with. I hope that we can continue to work together in some capacity and wish him the best of luck with his new job in Cambodia at Okra Solar.